Selected Publications

Data-Adaptive Estimation for Double-Robust Methods in Population-Based Cancer Epidemiology: Risk differences for lung cancer mortality by emergency presentation
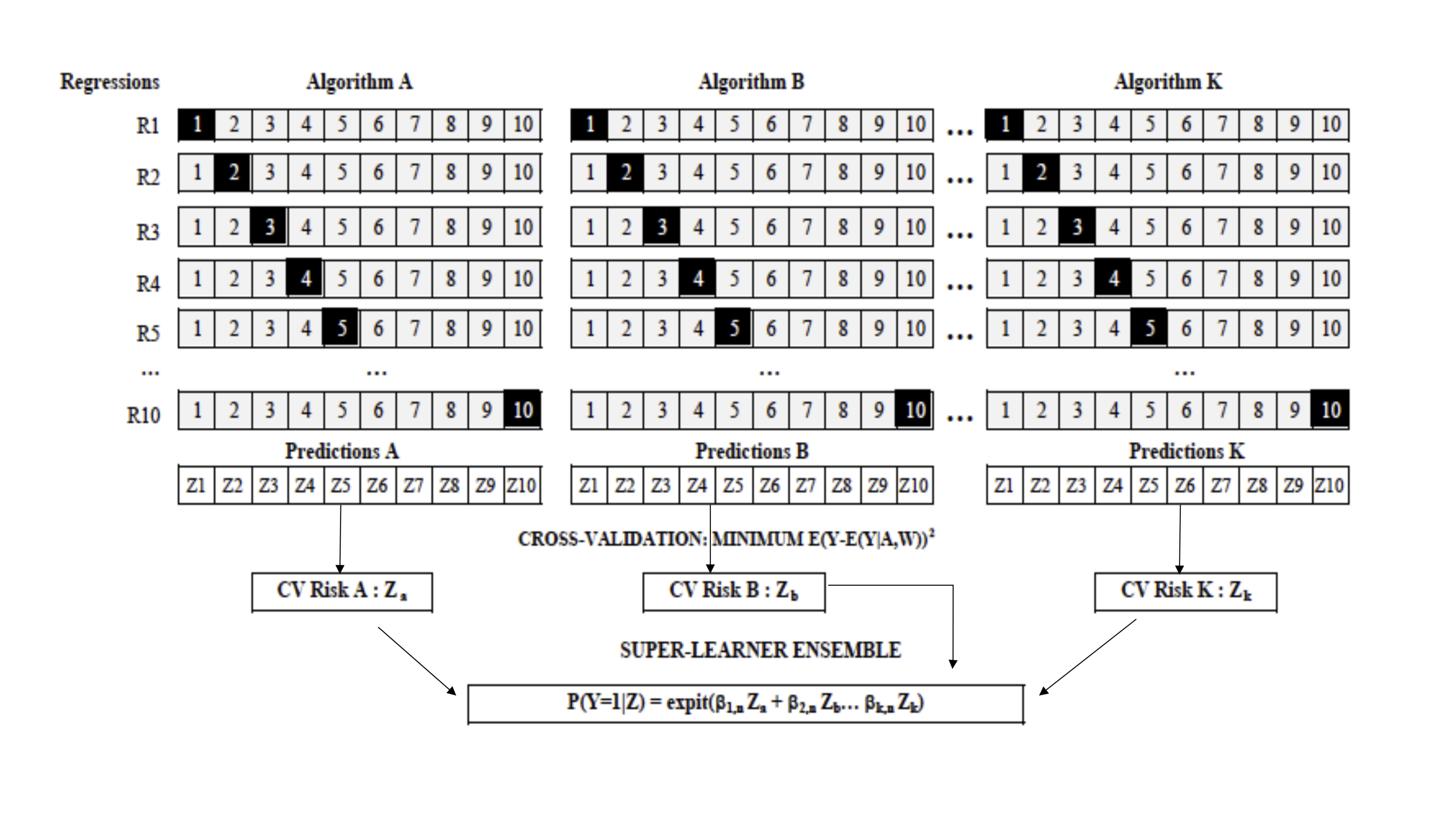
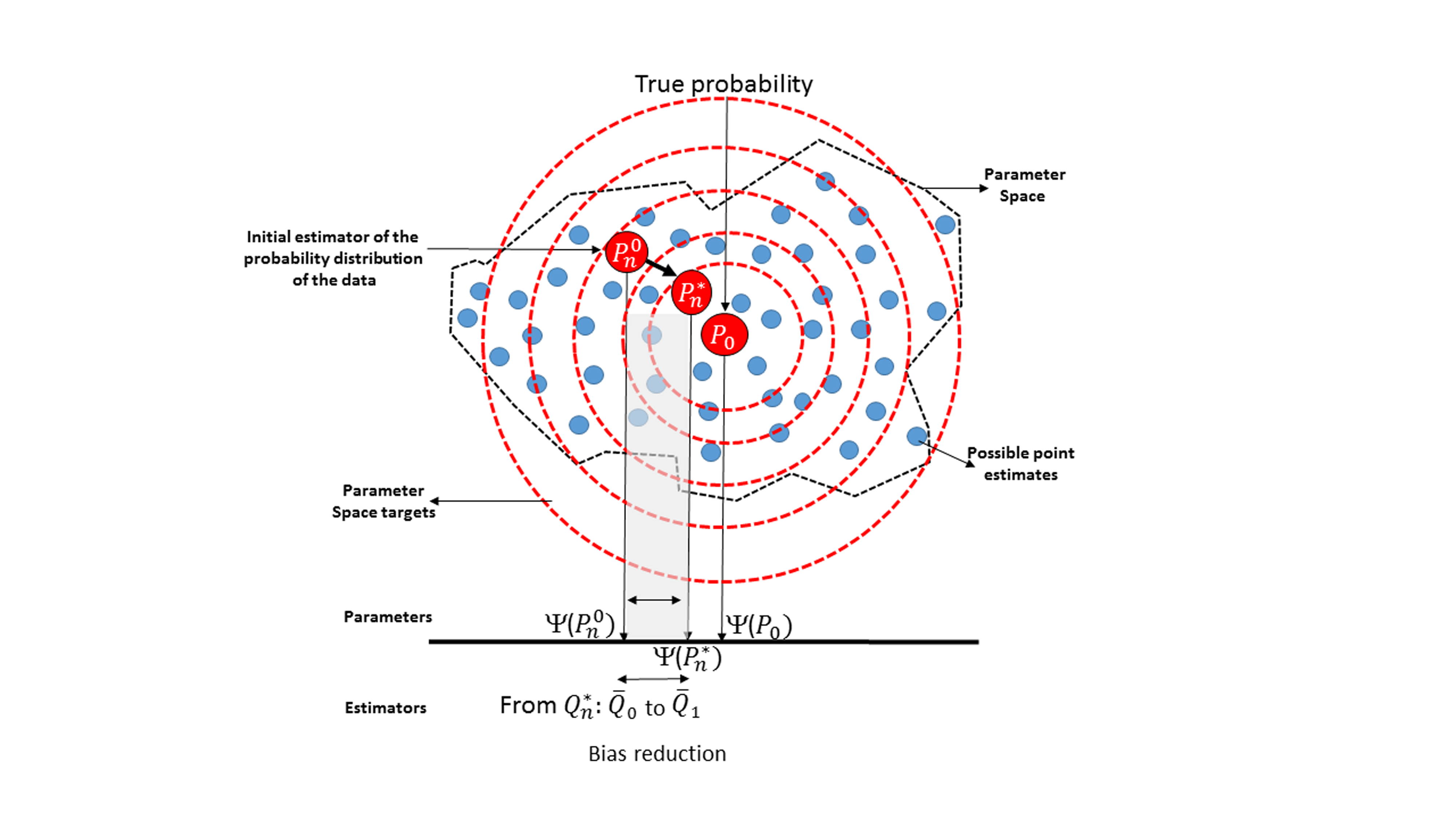
We propose a structural framework for population-based cancer epidemiology and evaluate the performance of double-robust estimators for a binary exposure in cancer mortality. We performed numerical analyses to study the bias and efficiency of these estimators. Furthermore, we compared two different model selection strategies based on 1) the Akaike and Bayesian Information Criteria and 2) machine-learning algorithms, and illustrated double-robust estimators’ performance in a real setting. In simulations with correctly specified models and near-positivity violations, all but the naïve estimators presented relatively good performance. However, the augmented inverse-probability treatment weighting estimator showed the largest relative bias. Under dual model misspecification and near-positivity violations, all double-robust estimators were biased. Nevertheless, the targeted maximum likelihood estimator showed the best bias-variance trade-off, more precise estimates, and appropriate 95% confidence interval coverage, supporting the use of the data-adaptive model selection strategies based on machine-learning algorithms. We applied these methods to estimate adjusted one-year mortality risk differences in 183,426 lung cancer patients diagnosed after admittance to an emergency department versus non-emergency cancer diagnosis in England, 2006–2013. The adjusted mortality risk (for patients diagnosed with lung cancer after admittance to an emergency department) was 16% higher in men and 18% higher in women, suggesting the importance of interventions targeting early detection of lung cancer signs and symptoms.
In AJE,
2017
Preprint
The `projects` parameter in `content/publication/tmle.md` references a project file, `content/project/TMLE`, which cannot be found. Please either set `projects = []` or fix the reference.
Custom Link
Deconstructing the smoking-preeclampsia paradox through a counterfactual framework
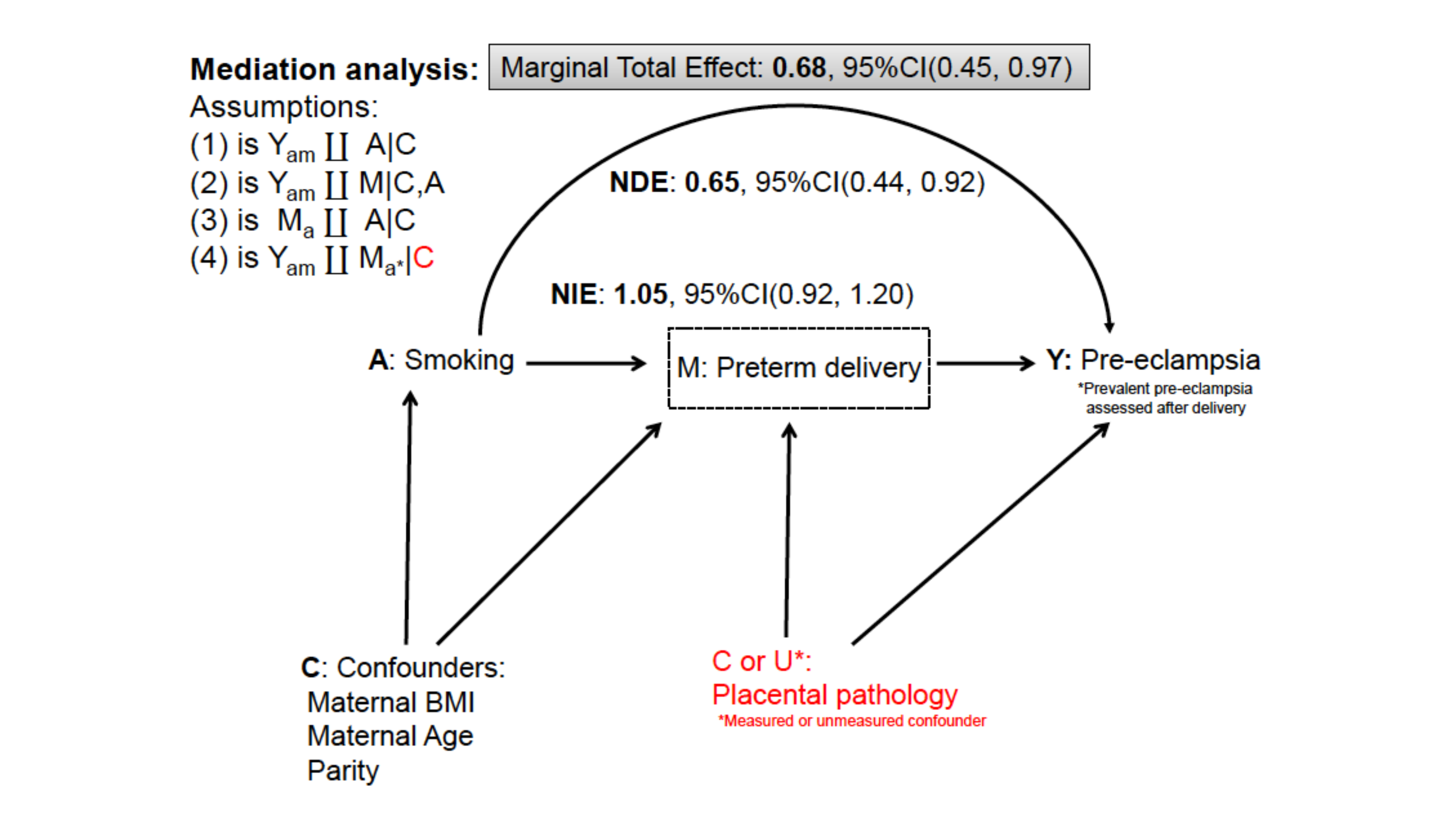
Although smoking during pregnancy may lead to many adverse outcomes, numerous studies have reported a paradoxical inverse association between maternal cigarette smoking during pregnancy and preeclampsia. Using a counterfactual framework we aimed to explore the structure of this paradox as being a consequence of selection bias. Using a case–control study nested in the Icelandic Birth Registry (1309 women), we show how this selection bias can be explored and corrected for. Cases were defined as any case of pregnancy induced hypertension or preeclampsia occurring after 20 weeks’ gestation and controls as normotensive mothers who gave birth in the same year. First, we used directed acyclic graphs to illustrate the common bias structure. Second, we used classical logistic regression and mediation analytic methods for dichotomous outcomes to explore the structure of the bias. Lastly, we performed both deterministic and probabilistic sensitivity analysis to estimate the amount of bias due to an uncontrolled confounder and corrected for it. The biased effect of smoking was estimated to reduce the odds of preeclampsia by 28 % (OR 0.72, 95 %CI 0.52, 0.99) and after stratification by gestational age at delivery (<37 vs. ≥37 gestation weeks) by 75 % (OR 0.25, 95 %CI 0.10, 0.68). In a mediation analysis, the natural indirect effect showed and OR > 1, revealing the structure of the paradox. The bias-adjusted estimation of the smoking effect on preeclampsia showed an OR of 1.22 (95 %CI 0.41, 6.53). The smoking-preeclampsia paradox appears to be an example of (1) selection bias most likely caused by studying cases prevalent at birth rather than all incident cases from conception in a pregnancy cohort, (2) omitting important confounders associated with both smoking and preeclampsia (preventing the outcome to develop) and (3) controlling for a collider (gestation weeks at delivery). Future studies need to consider these aspects when studying and interpreting the association between smoking and pregnancy outcomes.
In EJEP,
2016